The Yat-Kernel MLP in JAX/Flax NNX
#ml#kernels#interpretability#mlp#rkhs#yat#jax#flax#nnx#implementation#deep-learning
The explainer argued that if you put a finite, positive-definite kernel where the activation function used to be, an MLP stops being a stack of linear maps glued by a nonlinearity and becomes a kernel machine, with locality, attribution, geometry, capacity control, and a feature map you can write down. This is the implementation companion: build that layer in Flax NNX, turn each claim into an assert, and train the thing end to end. Every number and figure below is from a real run. The dimensions are tiny so the objects are legible.
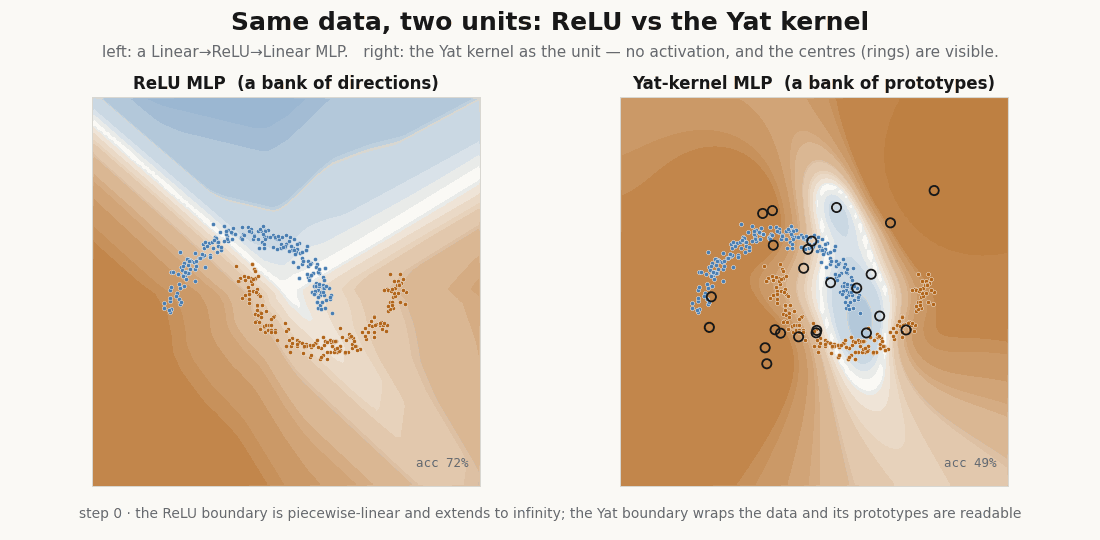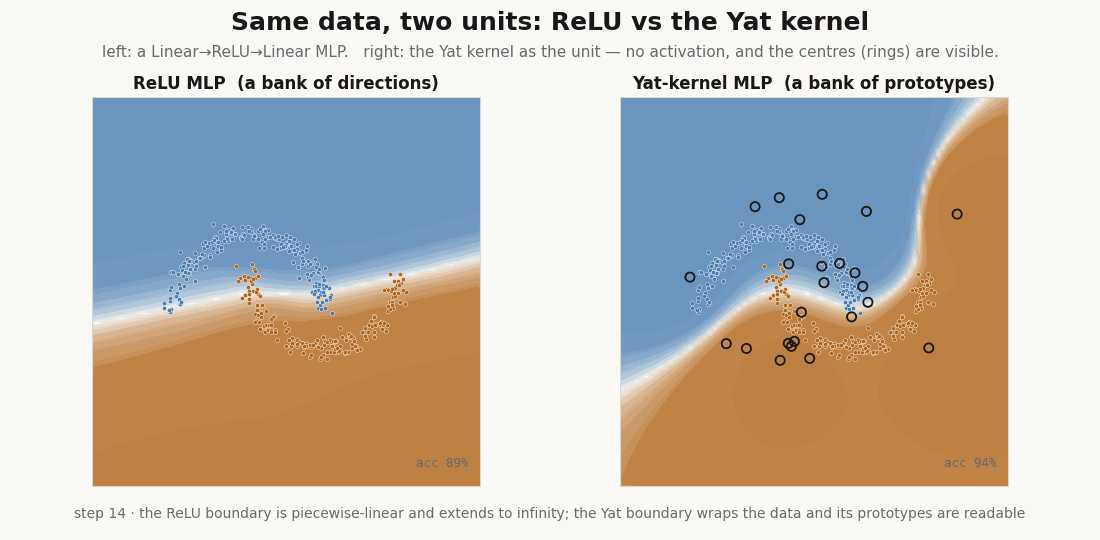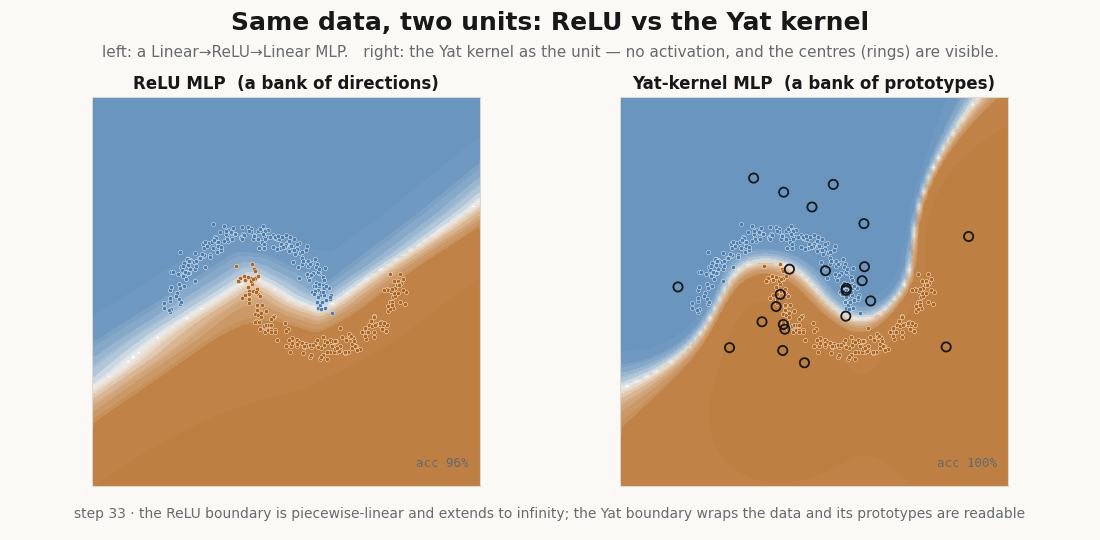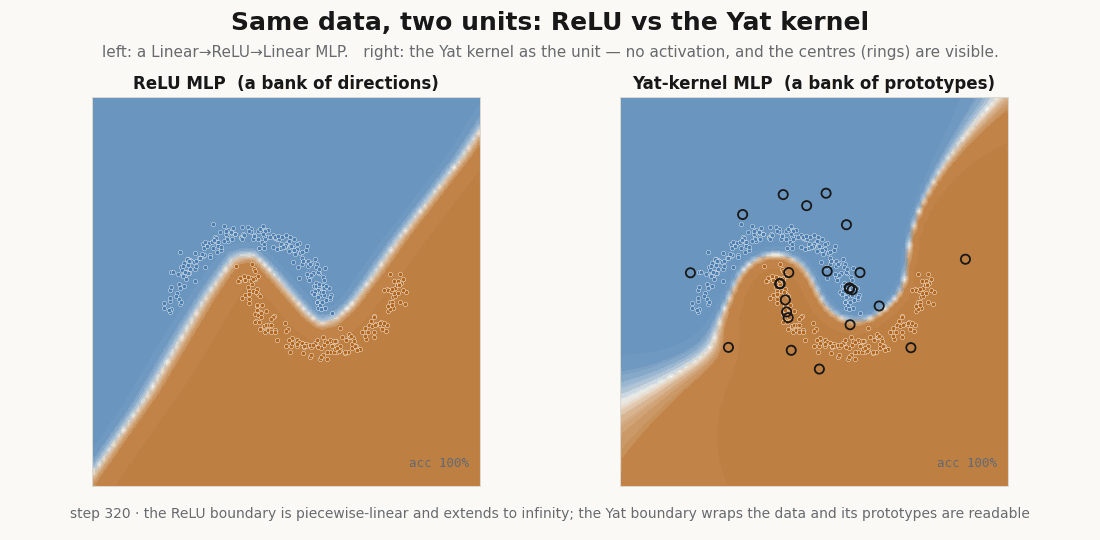
The unit
A Yat unit measures the input against a learned prototype with the kernel . A whole layer is a bank of these, and there is no activation function anywhere in it. In NNX the prototypes are the parameters; and are learned through a softplus so they stay admissible (, ).
import jax, jax.numpy as jnp
from flax import nnx
class YatLayer(nnx.Module):
"""A layer of Yat-kernel units. No activation function."""
def __init__(self, d_in, n_units, *, rngs: nnx.Rngs, b0=0.5, eps0=0.5):
self.W = nnx.Param(jax.random.normal(rngs.params(), (n_units, d_in)) * 0.7)
self.log_b = nnx.Param(jnp.full((), jnp.log(jnp.expm1(b0)))) # softplus⁻¹(b₀)
self.log_eps = nnx.Param(jnp.full((), jnp.log(jnp.expm1(eps0))))
def __call__(self, x): # x: [..., d_in]
b = jax.nn.softplus(self.log_b.value)
eps = jax.nn.softplus(self.log_eps.value)
dot = x @ self.W.value.T # [..., n_units] = x·Wᵤ
xn = jnp.sum(x ** 2, -1, keepdims=True) # ‖x‖²
wn = jnp.sum(self.W.value ** 2, -1) # ‖Wᵤ‖²
dist2 = xn + wn - 2.0 * dot # ‖x − Wᵤ‖²
return (dot + b) ** 2 / (dist2 + eps) # the kernel is the nonlinearityThe prototype is a point in input space, not a direction. A ReLU unit fires on an entire half-plane; the Yat unit has a single localized peak at its center. That difference is the whole story.
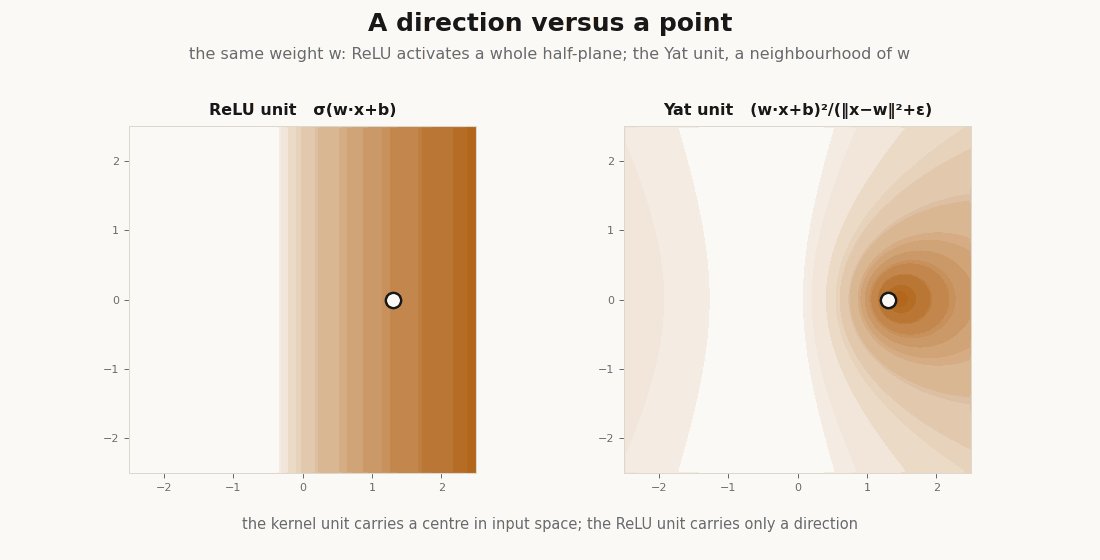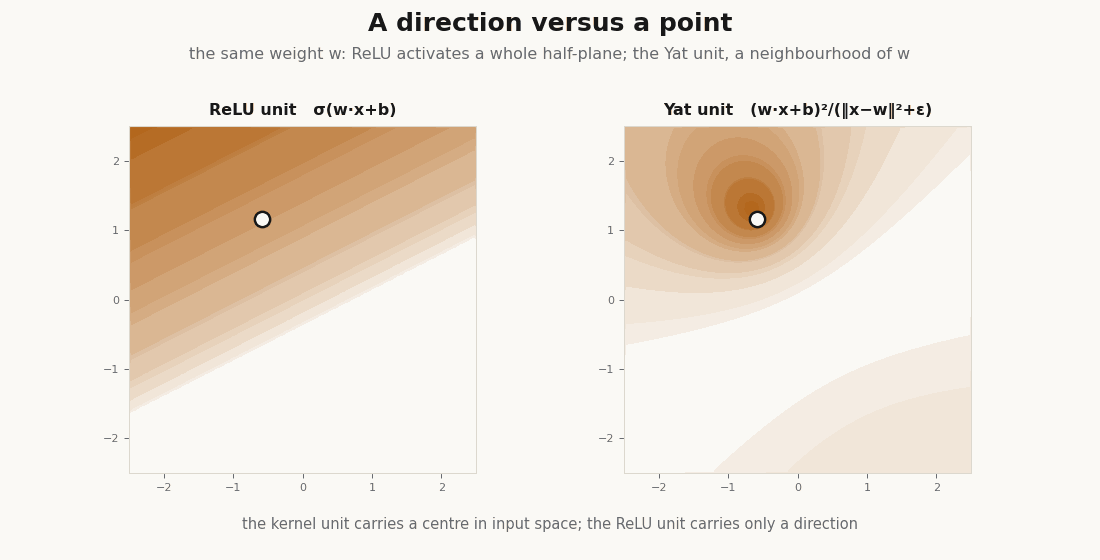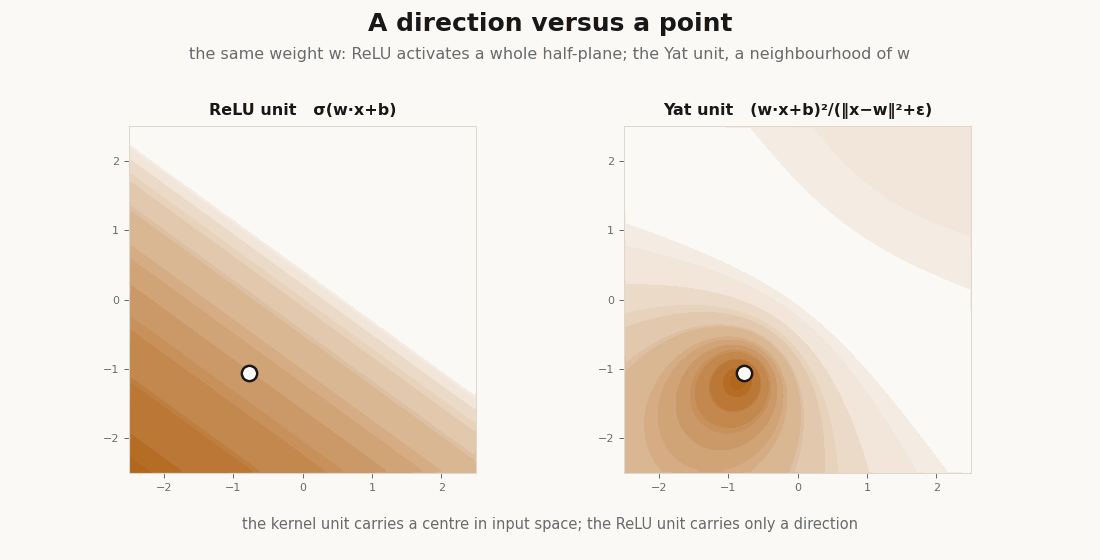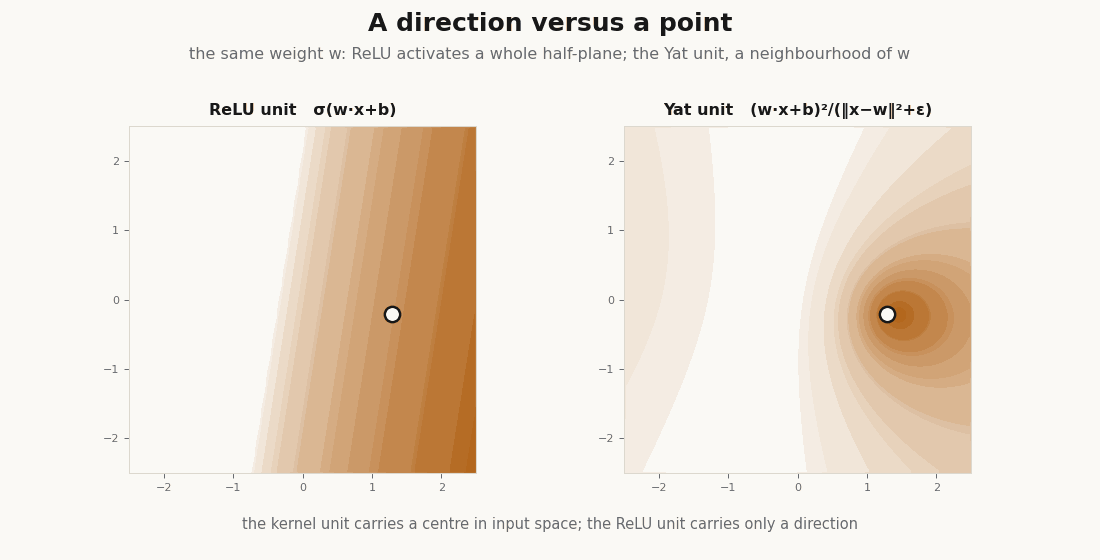
It is a kernel: positive definite and nonnegative
The two properties the explainer leans on are checkable in three lines. The Yat kernel is nonnegative (a square over a positive number) and positive definite (a Schur product of a polynomial and an inverse-multiquadric kernel), and these are independent facts, the unit has both.
def yat(a, b, bb=0.5, eps=0.5): # kernel matrix between two point sets
cross = a @ b.T
return (cross + bb) ** 2 / (jnp.sum(a**2, 1, keepdims=True) + jnp.sum(b**2, 1) - 2*cross + eps)
pts = jax.random.normal(jax.random.key(0), (16, 3))
G = yat(pts, pts) # Gram matrix
print("min eigenvalue:", float(jnp.linalg.eigvalsh(0.5 * (G + G.T)).min())) # ≈ 0.34 ≥ 0
print("all nonnegative:", bool((G >= 0).all())) # True
assert jnp.linalg.eigvalsh(0.5 * (G + G.T)).min() >= -1e-8 # positive semi-definite (Mercer)
assert (G >= 0).all() # nonnegative (convex weights)Positive-definiteness is what gives the unit an RKHS to reason in; nonnegativity is what lets the readout normalize into honest attribution. Bouhsine (2026) proves the kernel positive definite for and universal for .
The finite feature map, exactly
The word finite is not decoration. The Yat numerator is a degree-2 polynomial kernel, and a degree-2 polynomial kernel has an exact, finite-dimensional feature map, six numbers in two dimensions, in general. No infinite series to truncate, unlike the Gaussian RBF. Here it is, and here is the identity holding to machine precision:
s2 = jnp.sqrt(2.0)
def phi_x(x): # feature map of the input, R² → R⁶
x1, x2 = x[..., 0], x[..., 1]
return jnp.stack([x1**2, x2**2, s2*x1*x2, s2*x1, s2*x2, jnp.ones_like(x1)], -1)
def phi_W(W, b): # matching map of the prototype
W1, W2 = W[..., 0], W[..., 1]
return jnp.stack([W1**2, W2**2, s2*W1*W2, s2*b*W1, s2*b*W2, b**2*jnp.ones_like(W1)], -1)
A = jax.random.normal(jax.random.key(1), (20, 2))
Wp = jax.random.normal(jax.random.key(2), (20, 2)); b0 = 0.7
lhs = (jnp.sum(A * Wp, -1) + b0) ** 2
rhs = jnp.sum(phi_x(A) * phi_W(Wp, b0), -1)
print("max |error|:", float(jnp.max(jnp.abs(lhs - rhs)))) # ≈ 1.8e-15
assert jnp.allclose(lhs, rhs, atol=1e-8) # the feature map is exact, not approximateA finite feature map means a flat separator in feature space, which is a curved boundary in input space, the kernel trick. Fit that flat plane on data that no line can split, and watch it work.

Train it, with no activation function
A YatMLP is just a YatLayer followed by a linear readout. It trains like any other NNX module, except the only nonlinearity in the network is the kernel.
import optax
class YatMLP(nnx.Module):
def __init__(self, d_in, n_units, d_out, *, rngs: nnx.Rngs):
self.yat = YatLayer(d_in, n_units, rngs=rngs)
self.readout = nnx.Linear(n_units, d_out, use_bias=True, rngs=rngs)
def __call__(self, x):
return self.readout(self.yat(x)) # kernel activations → logits
model = YatMLP(d_in=2, n_units=24, d_out=2, rngs=nnx.Rngs(0))
optimizer = nnx.Optimizer(model, optax.adam(3e-2), wrt=nnx.Param)
@nnx.jit
def train_step(model, optimizer, X, y):
def loss_fn(model):
logits = model(X)
return optax.softmax_cross_entropy_with_integer_labels(logits, y).mean()
loss, grads = nnx.value_and_grad(loss_fn)(model)
optimizer.update(model, grads)
return loss
for step in range(320): # X, y are two-moons (see the figure)
loss = train_step(model, optimizer, X, y)
print("final loss:", float(loss)) # ≈ 2e-5
print("train accuracy:", float((model(X).argmax(-1) == y).mean())) # 1.0
print("learned b, ε:", float(jax.nn.softplus(model.yat.log_b.value)),
float(jax.nn.softplus(model.yat.log_eps.value))) # b → 1.02, ε → 0.25It reaches the data, and the prototypes do the reaching: they start scattered and migrate onto the moons, the kernel scalars and drifting to fit the scale. This is the rich, feature-learning regime, the opposite of the NTK’s frozen kernel (Jacot et al., 2018), and yet every step is an exact kernel machine.
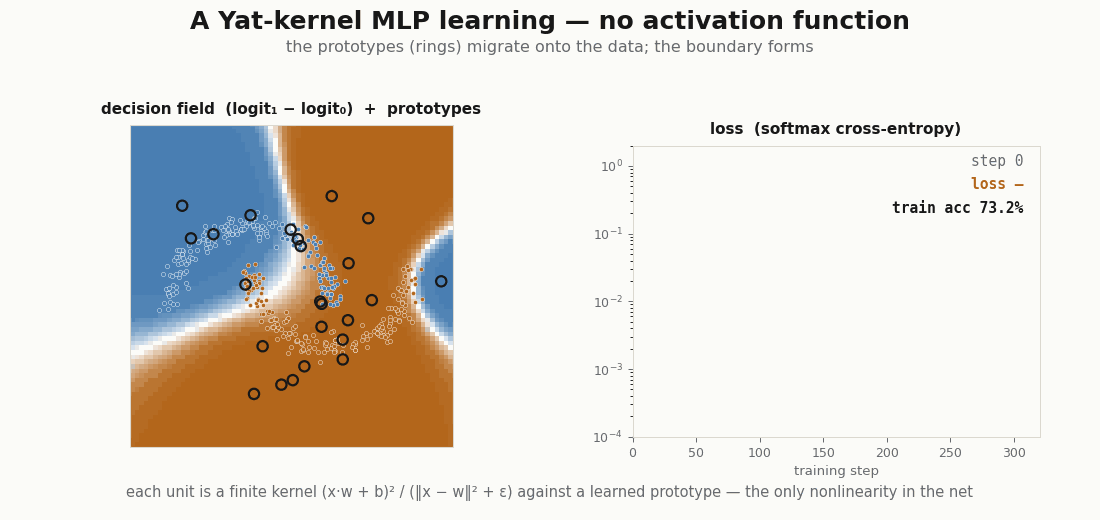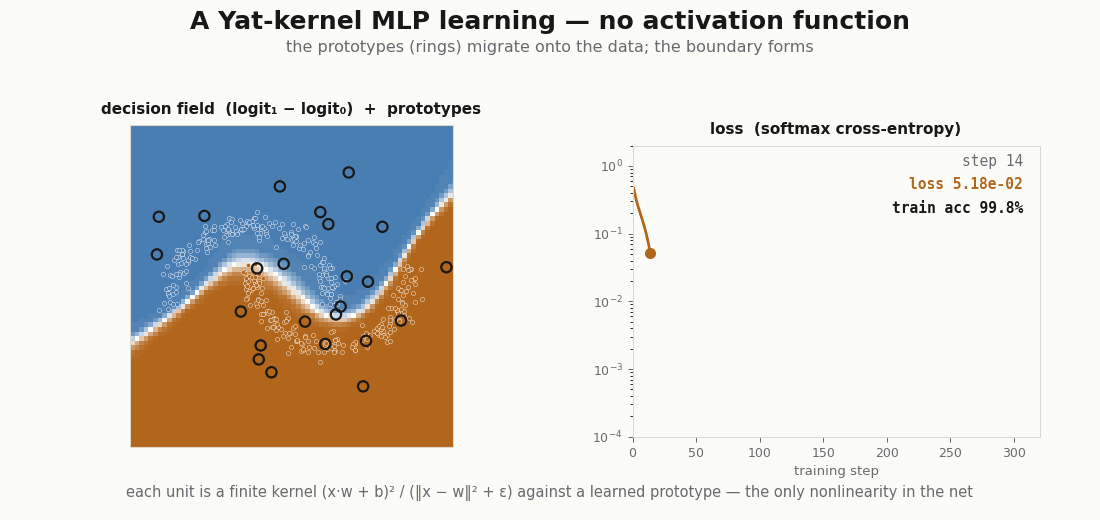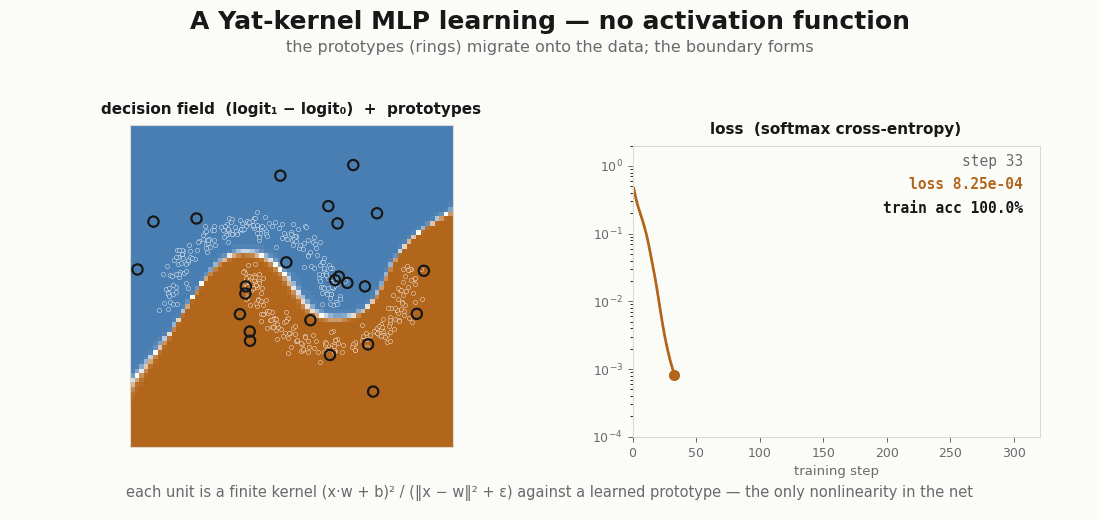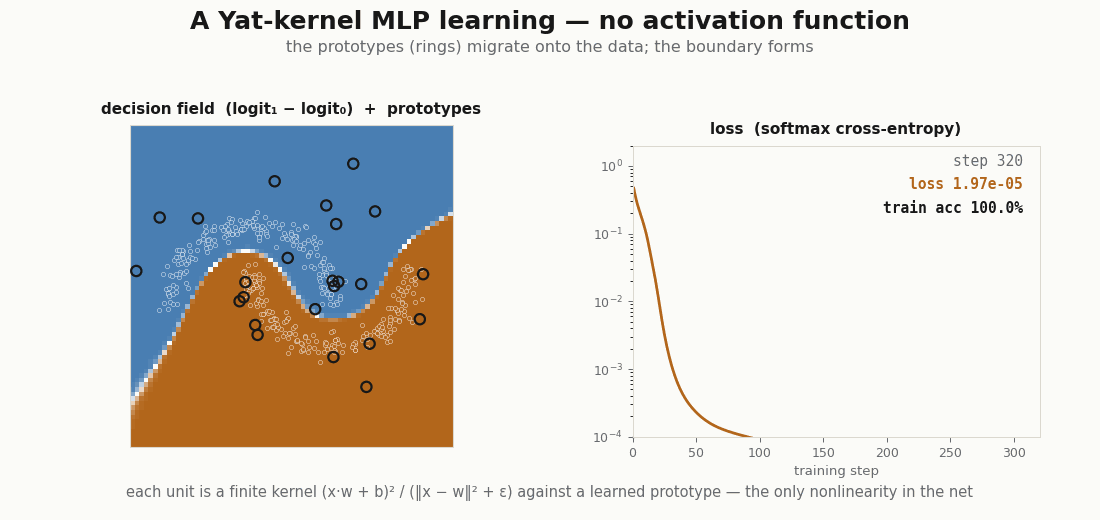
Lazy loading: the layer fires a handful of units
Because each unit is peaked at its center, only the prototypes near an input respond. The hidden layer is sparse by construction, which is the basis for fetching only the active units instead of evaluating the whole layer. A ReLU layer cannot do this, half its units fire on any input.
layer = YatLayer(2, 64, rngs=nnx.Rngs(0))
Xb = jax.random.normal(jax.random.key(3), (200, 2))
act = layer(Xb) # [200, 64] kernel activations
frac_yat = float(jnp.mean(act >= 0.18 * act.max(-1, keepdims=True)))
relu = jnp.maximum(Xb @ jax.random.normal(jax.random.key(4), (2, 64)), 0.0)
frac_relu = float(jnp.mean(relu > 0))
print(f"active fraction, Yat {frac_yat*100:.0f}% ReLU {frac_relu*100:.0f}%") # Yat 25% ReLU 50%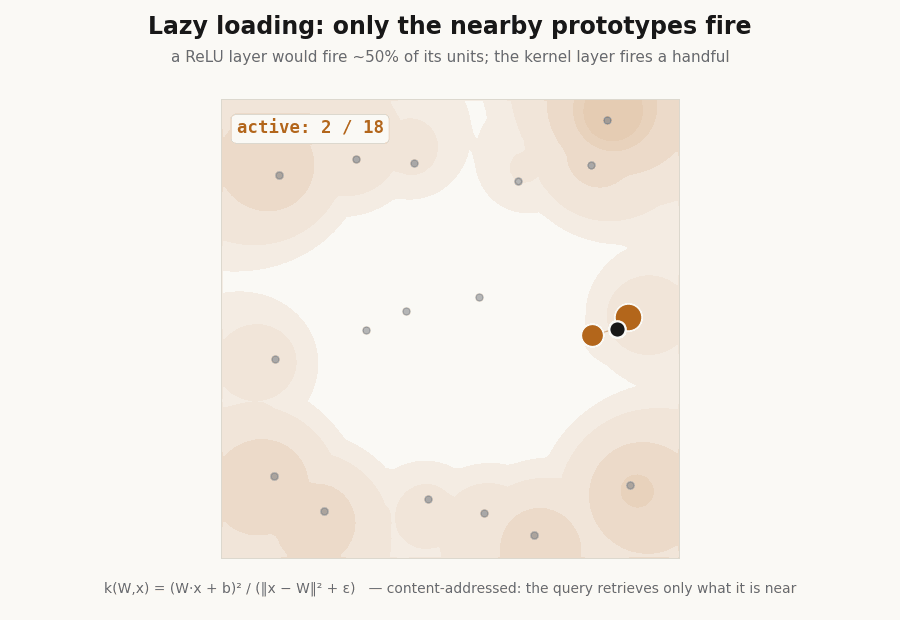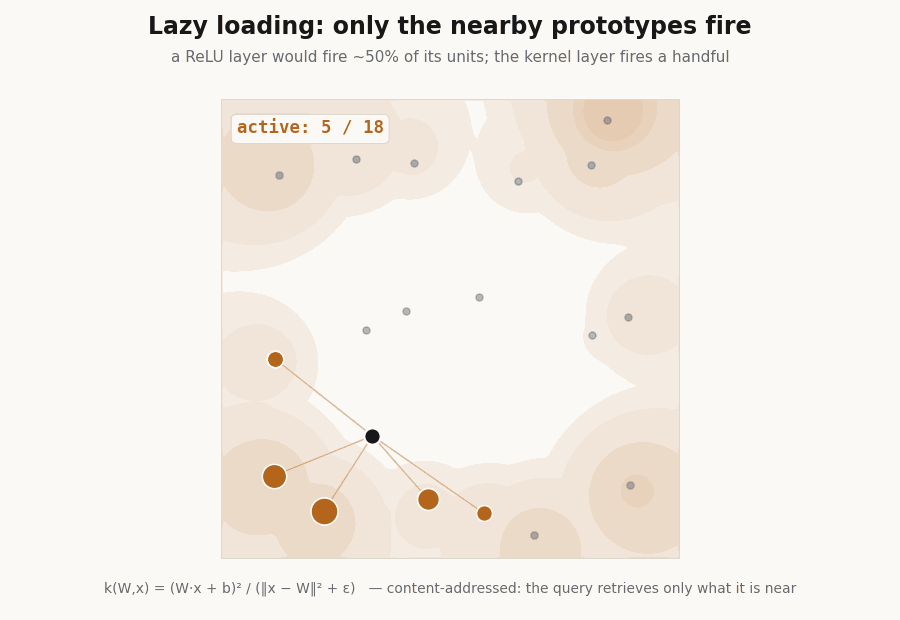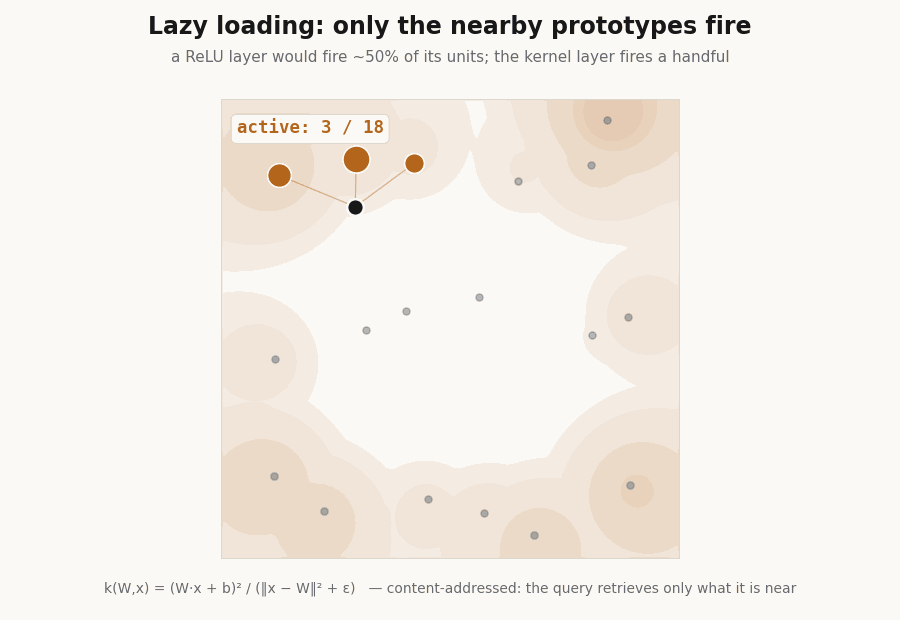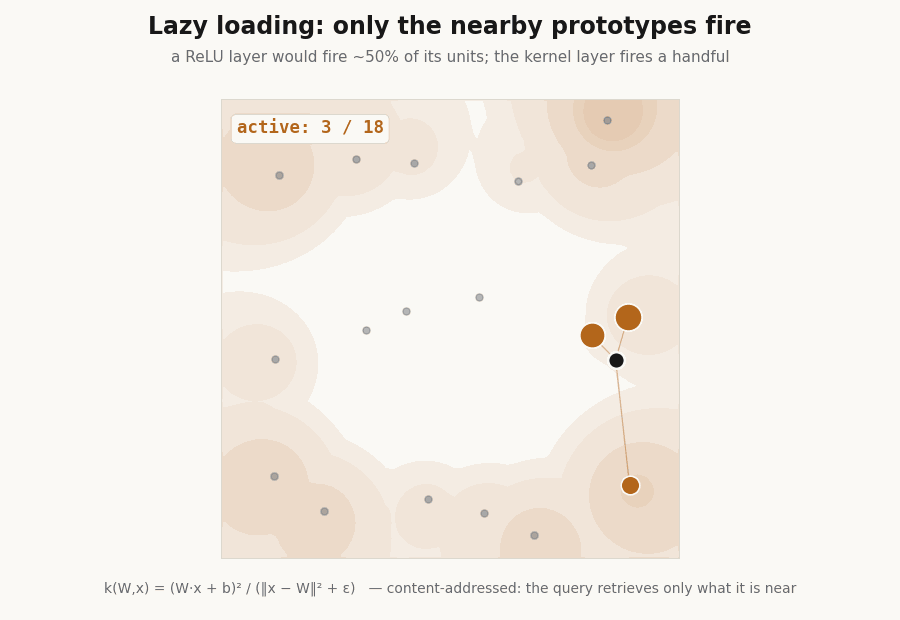
Bounded off the distribution
Drive a ReLU unit far from the data and it climbs without bound, a confident answer for an input it has never seen. The Yat unit stays bounded: its response far away is a fraction of its in-data peak, never an extrapolated cliff.
xs = jnp.linspace(-50, 50, 4001)
yat_1d = (xs + 0.6) ** 2 / (xs ** 2 + 0.3)
relu_1d = jnp.maximum(xs + 0.6, 0.0)
print("sup |Yat| :", float(jnp.max(yat_1d))) # 2.20, bounded over the whole range
print("sup ReLU :", float(jnp.max(relu_1d))) # 50.6, grows with the range
assert jnp.max(yat_1d) < 5.0 # bounded no matter how far off-distribution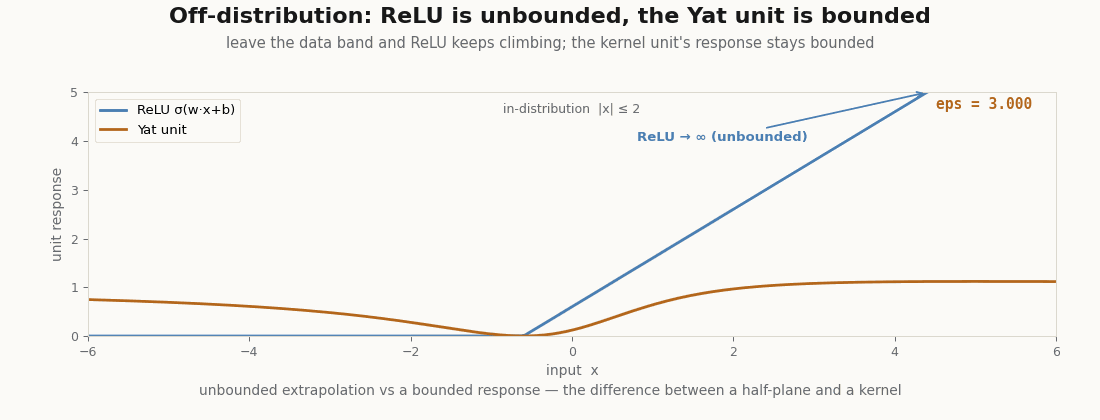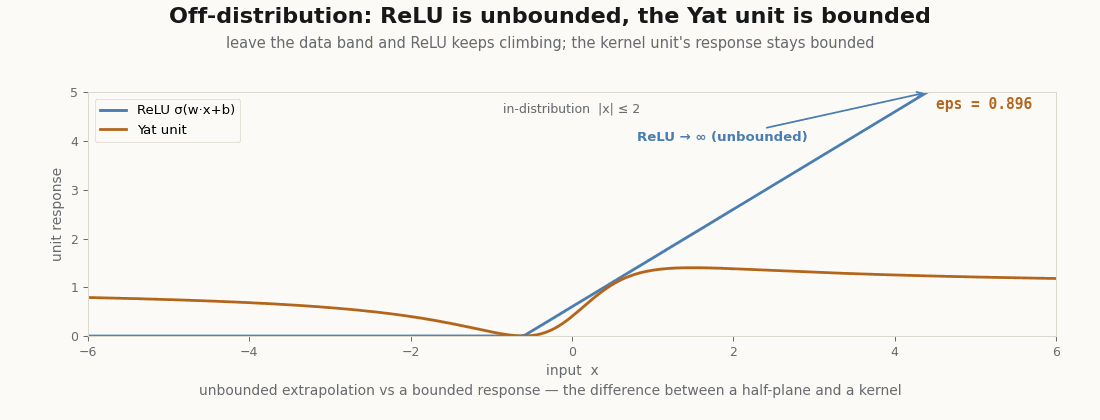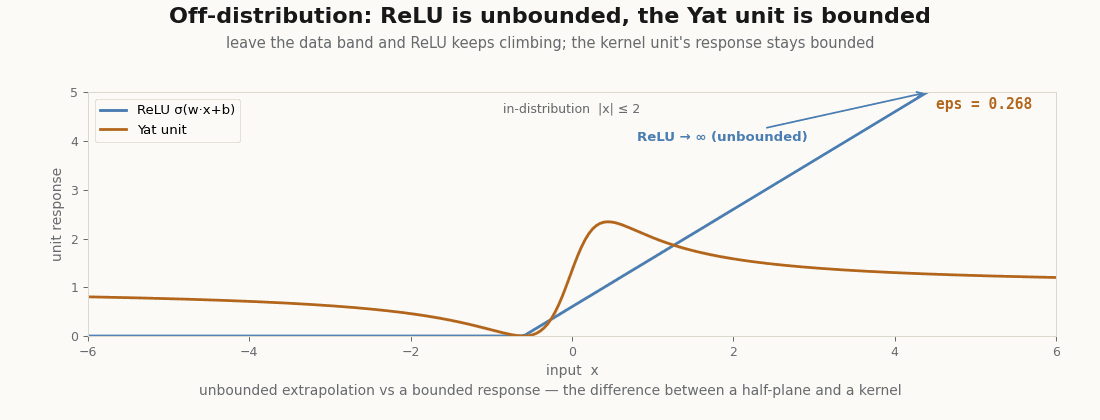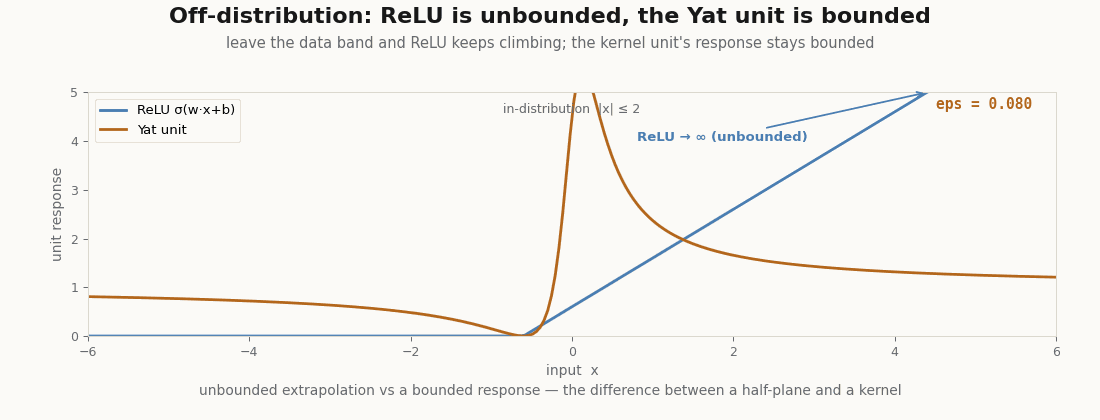
Capacity you can compute, and a force that never vanishes
The RKHS norm of a unit at its peak is the computable scalar , a real measure of how sharply it is tuned, and a direct target for regularization through . And because the kernel is smooth everywhere, the gradient that pulls a prototype toward its data never vanishes, there is no dead half-space, the way a saturated ReLU has.
W0 = jnp.array([1.0, 0.5])
print("capacity (‖W‖²+b)²/ε:", float((jnp.sum(W0**2) + 0.5) ** 2 / 0.25)) # 12.25
# the force on a prototype = −∇ of an objective that makes it a class detector
def k(P, X, b=0.5, eps=0.4):
cross = X @ P
return (cross + b) ** 2 / (jnp.sum(X**2, 1) + jnp.sum(P**2) - 2*cross + eps)
L = lambda P: k(P, XB).mean() - k(P, XA).mean() # attract to A, repel from B
forces = jax.vmap(jax.grad(L))(jax.random.normal(jax.random.key(7), (50, 2)) * 1.5)
print("min ‖force‖ over 50 probes:", float(jnp.min(jnp.linalg.norm(forces, axis=1)))) # 0.32 > 0
assert jnp.min(jnp.linalg.norm(forces, axis=1)) > 1e-4 # force everywhere, no dead zone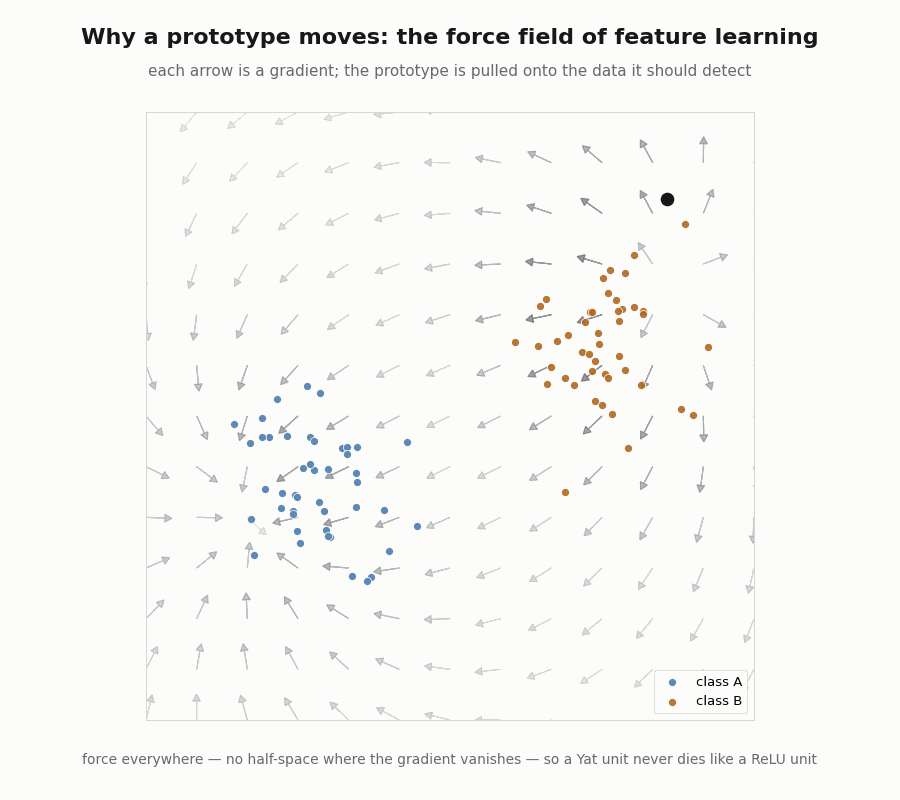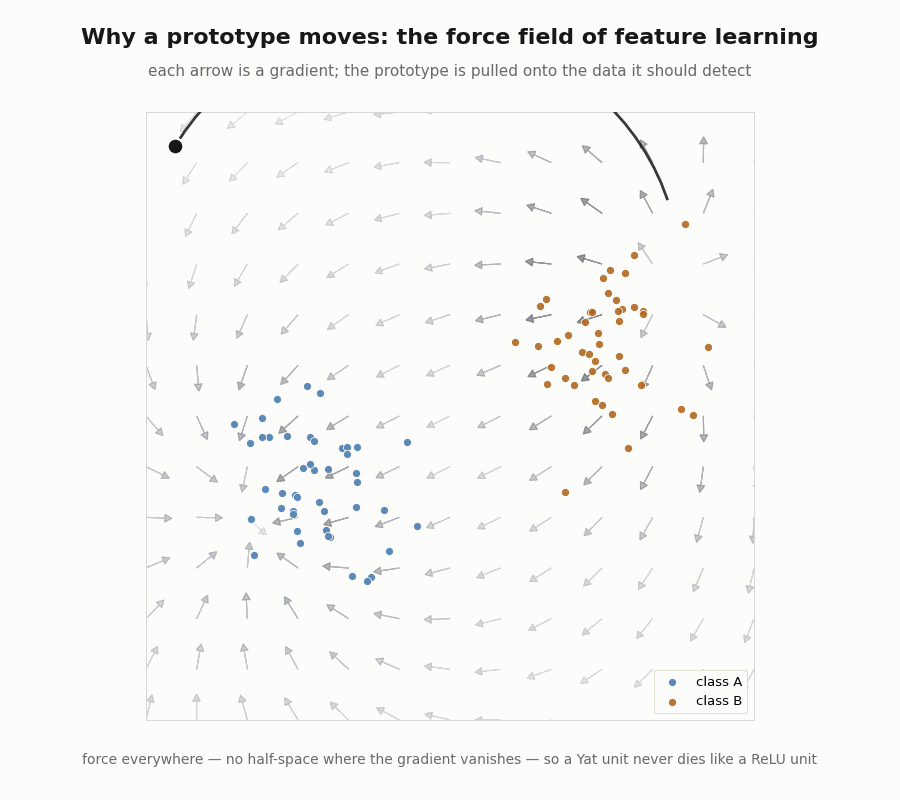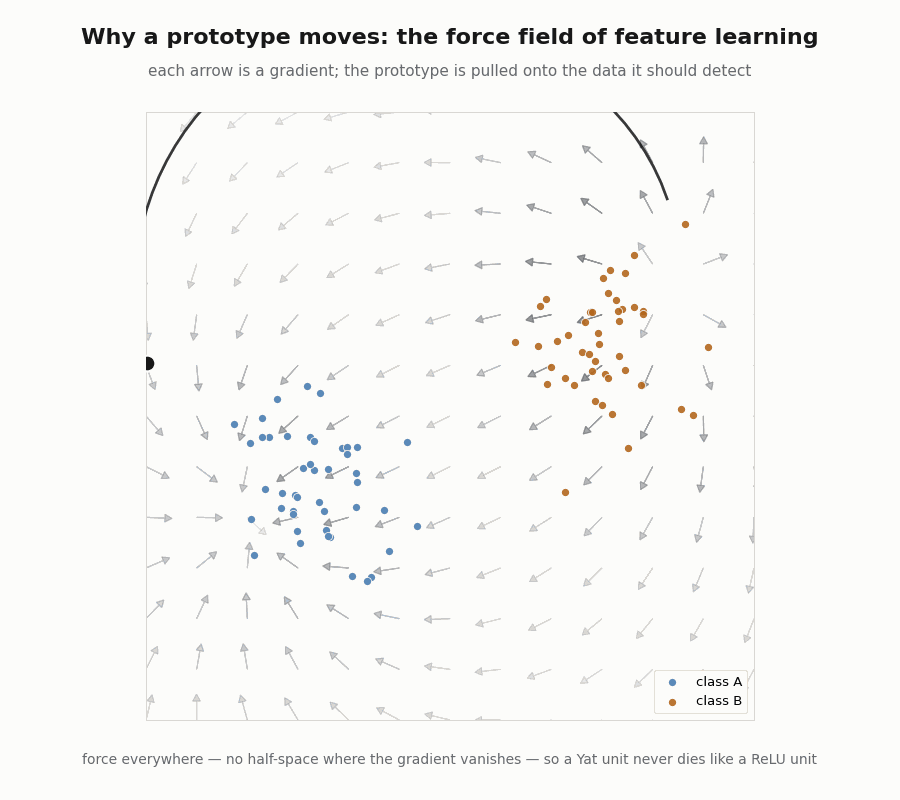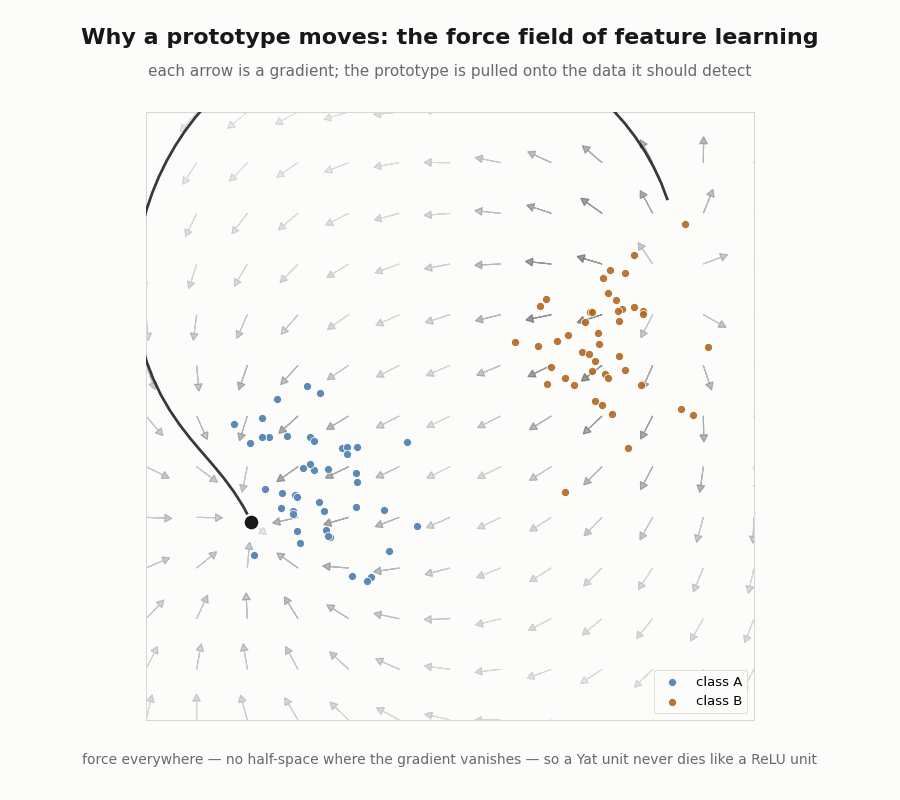
What this leaves out
This is a teaching implementation, not a drop-in transformer FFN, that is an empirical question the explainer is careful not to prejudge. Three honest notes. The distance term costs more memory traffic than a single GEMM, even though it reduces to a matmul plus two norm vectors. The canonical block is , not stacked kernels. And prototype initialization matters more than weight initialization in a ReLU net, because a center is a location, not just a scale. None of that changes the object: a layer whose primitive is a finite, positive-definite kernel, and whose every affordance, locality, attribution, geometry, capacity, a feature map, is a property of that kernel rather than something bolted on after the fact.
The Yat kernel and its universality are from Bouhsine (2026). Flax NNX Module API; the representer theorem from Schölkopf et al. (2001); the Neural Tangent Kernel from Jacot et al. (2018); random features from Rahimi & Recht (2007). The conceptual companion is What a Finite Kernel Buys an MLP.
Cite as
Bouhsine, T. (). The Yat-Kernel MLP in JAX/Flax NNX. Records of the !mmortal Data Scientist. https://tahabouhsine.com/blog/yat-mlp-jax-flax-nnx/
BibTeX
@misc{bouhsine2026yatmlpjaxflaxnnx,
author = {Bouhsine, Taha},
title = {The Yat-Kernel MLP in JAX/Flax NNX},
year = {2026},
month = {jun},
howpublished = {\url{https://tahabouhsine.com/blog/yat-mlp-jax-flax-nnx/}},
note = {Blog post, Records of the !mmortal Data Scientist}
}References
- (1909). Functions of Positive and Negative Type, and their Connection with the Theory of Integral Equations. Philosophical Transactions of the Royal Society A 209, 415–446.
- (2001). A Generalized Representer Theorem. COLT 2001, 416–426.
- (2007). Random Features for Large-Scale Kernel Machines. NeurIPS 2007.
- (2018). Neural Tangent Kernel: Convergence and Generalization in Neural Networks. NeurIPS 2018.arXiv:1806.07572
- (2026). A Universal Reproducing Kernel Hilbert Space from Polynomial Alignment and IMQ Distance. arXiv:2605.03262